NOSQL
优点
1.解决CPU及内存压力
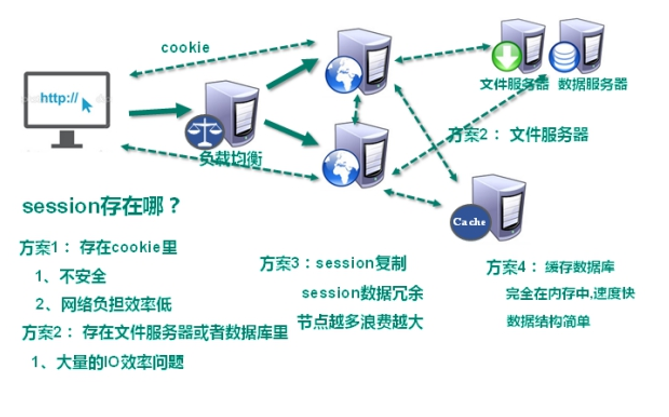
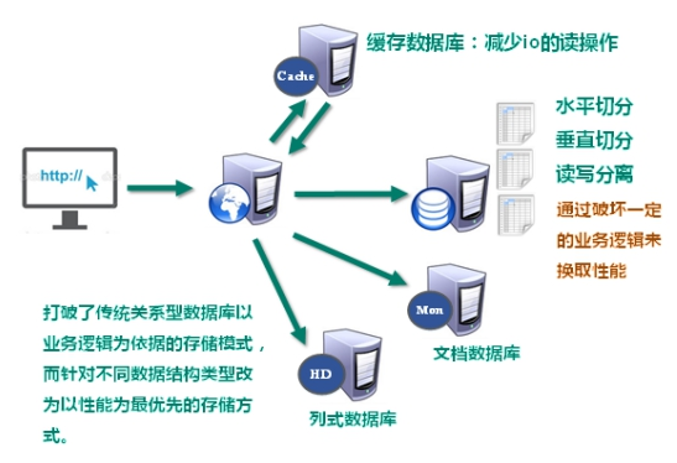
2.解决IO压力
概述
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库。
NoSQL 不依赖业务逻辑方式存储,而以简单的key-value模式存储。因此大大的增加了数据库的扩展能力。
1.不遵循SQL标准。
2.不支持ACID。
3.远超于SQL的性能。
NoSQL适用场景
1.对数据高并发的读写
2.海量数据的读写
3.对数据高可扩展性的
NoSQL不适用场景
1.需要事务支持
2.基于sql的结构化查询存储,处理复杂的关系,需要即席查询。
3.(用不着sql的和用了sql也不行的情况,请考虑用NoSq)
常用五大数据类型
Redis键
keys *查看当前库所有key (匹配:keys *1)
exists key 判断某个key是否存在
type key 查看你的key是什么类型
del key 删除指定的key数据
unlink key 根据value选择非阻塞删除
仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作。
expire key 10 10秒钟:为给定的key设置过期时间
ttl key 查看还有多少秒过期,-1表示永不过期,-2表示已过期
select 命令切换数据库
dbsize 查看当前数据库的key的数量
flushdb 清空当前库
flushall 通杀全部库
Redis字符串(String)
简介
String是Redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M
常用命令
set
*NX:当数据库中key不存在时,可以将key-value添加数据库
*XX:当数据库中key存在时,可以将key-value添加数据库,与NX参数互斥
*EX:key的超时秒数
*PX:key的超时毫秒数,与EX互斥
get
append
strlen
setnx
incr
将 key 中储存的数字值增1
只能对数字值操作,如果为空,新增值为1
decr
将 key 中储存的数字值减1
只能对数字值操作,如果为空,新增值为-1
incrby / decrby
mset
同时设置一个或多个 key-value对
mget
同时获取一个或多个 value
msetnx
同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。
由于原子性,有一个失败则都失败
getrange
获得值的范围,类似java中的substring,前包,后包
setrange
用
setex
设置键值的同时,设置过期时间,单位秒。
getset
以新换旧,设置了新值同时获得旧值。
Java 中的 i++ 是原子操作吗?
不是原子操作
所谓原子操作是指不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)
在单线程中, 能够在单条指令中完成的操作都可以认为是”原子操作”,因为中断只能发生于指令之间
在多线程中,不能被其它进程(线程)打断的操作就叫原子操作
Redis 单命令的原子性主要得益于 Redis 的单线程
给定 i = 0,两个线程分别执行 i++ 100次,值是多少?
2~200
数据结构
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配.
内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
Redis列表(List)
简介
单键多值
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
常用命令
lpush/rpush
lpop/rpop
rpop|push
lrange
按照索引下标获得元素(从左到右)
lrange mylist 0 -1 0左边第一个,-1右边第一个,(0-1表示获取所有)
lindex
llen
linsert
lrem
lset
数据结构
List的数据结构为快速链表quickList。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。
它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
当数据量比较多的时候才会改成quicklist。
因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。
Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
Redis集合(Set)
简介
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的*复杂度都是***O(1)**。
一个算法,随着数据的增加,执行时间的长短,如果是O(1),数据增加,查找数据的时间不变
常用命令
sadd
将一个或多个 member 元素加入到集合 key 中,已经存在的 member 元素将被忽略
smembers
sismember
scard
srem
spop
srandmember
smove
sinter
sunion
sdiff
数据结构
Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
Redis哈希(Hash)
简介
Redis hash 是一个键值对集合。
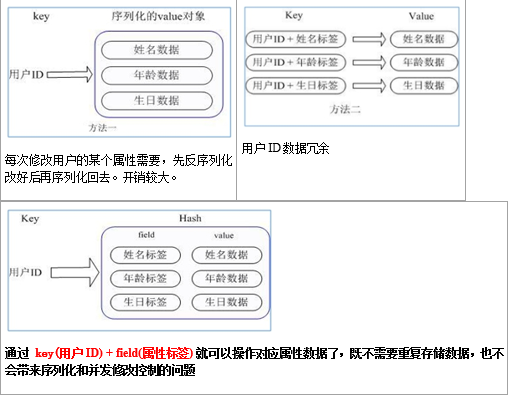
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
类似Java里面的Map<String,Object>
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储
常用命令
hset
hget
hset
hexists
hkeys
hvals
hincrby
hsetnx
数据结构
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable
Redis有序集合(Zset)
简介
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
常用命令
zadd
将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
zrange
返回有序集 key 中,下标在
带WITHSCORES,可以让分数一起和值返回到结果集。
zrangebyscore key minmax [withscores] [limit offset count]
返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
zrevrangebyscore key maxmin [withscores] [limit offset count]
同上,改为从大到小排列。
zincrby
zrem
zcount
zrank
数据结构
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
跳表
1、简介
有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现,可以用数组、平衡树、链表等。数组不便元素的插入、删除;平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。Redis采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。
2、实例
对比有序链表和跳跃表,从链表中查询出51
(1) 有序链表

要查找值为51的元素,需要从第一个元素开始依次查找、比较才能找到。共需要6次比较。
(2) 跳表
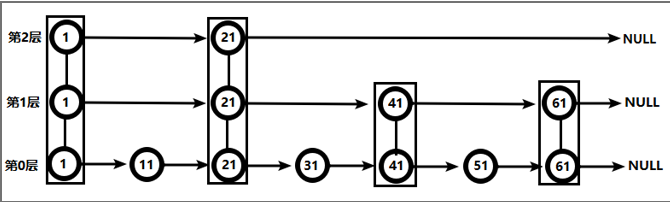
从第2层开始,1节点比51节点小,向后比较。
21节点比51节点小,继续向后比较,后面就是NULL了,所以从21节点向下到第1层
在第1层,41节点比51节点小,继续向后,61节点比51节点大,所以从41向下
在第0层,51节点为要查找的节点,节点被找到,共查找4次。
从此可以看出跳跃表比有序链表效率要高
Redis的三种新数据类型
Bitmaps
简介
现代计算机用二进制(位) 作为信息的基础单位, 1个字节等于8位, 例如“abc”字符串是由3个字节组成, 但实际在计算机存储时将其用二进制表示, “abc”分别对应的ASCII码分别是97、 98、 99, 对应的二进制分别是01100001、 01100010和01100011,如下图

合理地使用操作位能够有效地提高内存使用率和开发效率。
Redis提供了Bitmaps这个“数据类型”可以实现对位的操作:
(1) Bitmaps本身不是一种数据类型, 实际上它就是字符串(key-value) , 但是它可以对字符串的位进行操作。
(2) Bitmaps单独提供了一套命令, 所以在Redis中使用Bitmaps和使用字符串的方法不太相同。 可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。

命令
1、setbit
(1)格式
setbit
*offset:偏移量从0开始
(2)实例
每个独立用户是否访问过网站存放在Bitmaps中, 将访问的用户记做1, 没有访问的用户记做0, 用偏移量作为用户的id。
设置键的第offset个位的值(从0算起) , 假设现在有20个用户,userid=1, 6, 11, 15, 19的用户对网站进行了访问, 那么当前Bitmaps初始化结果如图
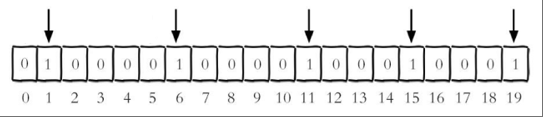
unique:users:20201106代表2020-11-06这天的独立访问用户的Bitmaps
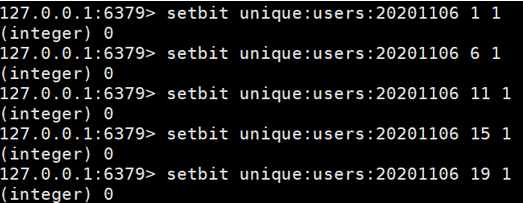
注:
很多应用的用户id以一个指定数字(例如10000) 开头, 直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费, 通常的做法是每次做setbit操作时将用户id减去这个指定数字。
在第一次初始化Bitmaps时, 假如偏移量非常大, 那么整个初始化过程执行会比较慢, 可能会造成Redis的阻塞。
2、getbit
(1)格式
getbit
获取键的第offset位的值(从0开始算)
(2)实例
获取id=8的用户是否在2020-11-06这天访问过, 返回0说明没有访问过:
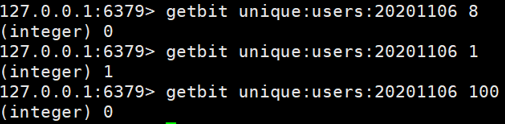
注:因为100根本不存在,所以也是返回0
3、bitcount
统计字符串被设置为1的bit数。一般情况下,给定的整个字符串都会被进行计数,通过指定额外的 start 或 end 参数,可以让计数只在特定的位上进行。start 和 end 参数的设置,都可以使用负数值:比如 -1 表示最后一个位,而 -2 表示倒数第二个位,start、end 是指bit组的字节的下标数,二者皆包含。
(1)格式
bitcount
举例: K1 【01000001 01000000 00000000 00100001】,对应【0,1,2,3】
bitcount K1 1 2 : 统计下标1、2字节组中bit=1的个数,即01000000 00000000
–》bitcount K1 1 2 –》1
bitcount K1 1 3 : 统计下标1、2字节组中bit=1的个数,即01000000 00000000 00100001
–》bitcount K1 1 3 –》3
bitcount K1 0 -2 : 统计下标0到下标倒数第2,字节组中bit=1的个数,即01000001 01000000 00000000
–》bitcount K1 0 -2 –》3
注意:redis的setbit设置或清除的是bit位置,而bitcount计算的是byte位置。
4、bitop
(1)格式
bitop and(or/not/xor)
bitop是一个复合操作, 它可以做多个Bitmaps的and(交集) 、 or(并集) 、 not(非) 、 xor(异或) 操作并将结果保存在destkey中。
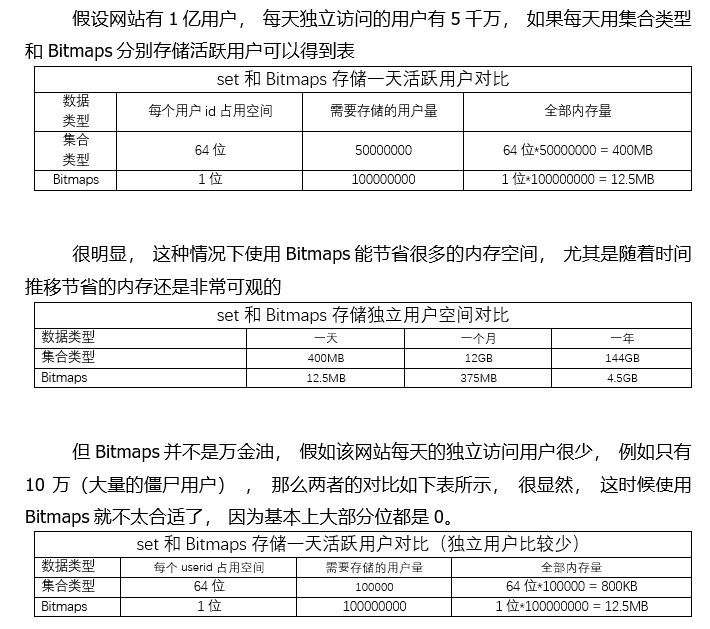
Bitmaps与set对比
HyperLogLog
简介
在工作当中,我们经常会遇到与统计相关的功能需求,比如统计网站PV(PageView页面访问量),可以使用Redis的incr、incrby轻松实现。
但像UV(UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题有很多种方案:
(1)数据存储在MySQL表中,使用distinct count计算不重复个数
(2)使用Redis提供的hash、set、bitmaps等数据结构来处理
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。
能否能够降低一定的精度来平衡存储空间?Redis推出了HyperLogLog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
命令
1、pfadd
(1)格式
pfadd
将所有元素添加到指定HyperLogLog数据结构中。如果执行命令后HLL估计的近似基数发生变化,则返回1,否则返回0。
2、pfcount
(1)格式
pfcount
3、pfmerge
(1)格式
pfmerge
Geospatial
简介
Redis 3.2 中增加了对GEO类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
命令
1、geoadd
(1)格式
geoadd
2、geopos
(1)格式
geopos
3、geodist
(1)格式
geodist
4、georadius
(1)格式
georadius
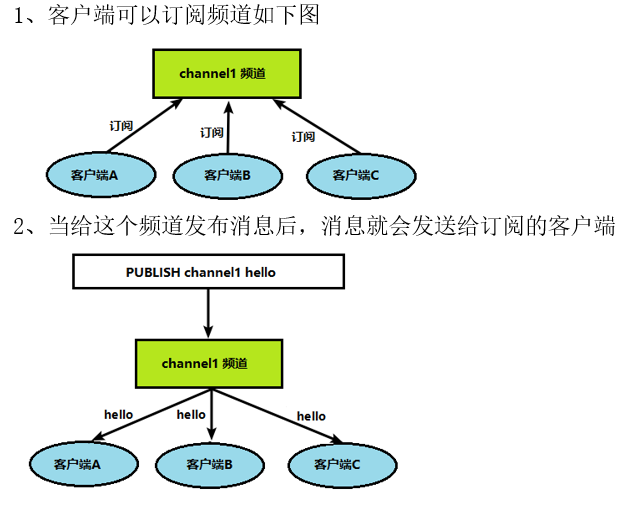
Redis的发布和订阅
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
Redis 客户端可以订阅任意数量的频道。
Jedis
引入jar包
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>Jedis-API
Key
jedis.set("k1", "v1");
jedis.set("k2", "v2");
jedis.set("k3", "v3");
Set<String> keys = jedis.keys("*");
System.out.println(keys.size());
for (String key : keys) {
System.out.println(key);
}
System.out.println(jedis.exists("k1"));
System.out.println(jedis.ttl("k1"));
System.out.println(jedis.get("k1"));String
jedis.mset("str1","v1","str2","v2","str3","v3");
System.out.println(jedis.mget("str1","str2","str3"));List
List<String> list = jedis.lrange("mylist",0,-1);
for (String element : list) {
System.out.println(element);
}
set
jedis.sadd("orders", "order01");
jedis.sadd("orders", "order02");
jedis.sadd("orders", "order03");
jedis.sadd("orders", "order04");
Set<String> smembers = jedis.smembers("orders");
for (String order : smembers) {
System.out.println(order);
}
jedis.srem("orders", "order02");
hash
jedis.hset("hash1","userName","lisi");
System.out.println(jedis.hget("hash1","userName"));
Map<String,String> map = new HashMap<String,String>();
map.put("telphone","13810169999");
map.put("address","atguigu");
map.put("email","abc@163.com");
jedis.hmset("hash2",map);
List<String> result = jedis.hmget("hash2", "telphone","email");
for (String element : result) {
System.out.println(element);
}Zset
jedis.zadd("zset01", 100d, "z3");
jedis.zadd("zset01", 90d, "l4");
jedis.zadd("zset01", 80d, "w5");
jedis.zadd("zset01", 70d, "z6");
Set<String> zrange = jedis.zrange("zset01", 0, -1);
for (String e : zrange) {
System.out.println(e);
}
Jedis完成手机验证码功能
public class PhoneCode {
public static void main(String[] args) {
verifyCode("15736918299");
getRedisCode("15736918299", "635867");
}
public static void getRedisCode(String phone, String code){
Jedis jedis = new Jedis("Redis的IP地址", 端口号);
jedis.auth("Redis的登录密码");
String codeKey = "VerifyCode" + phone + ":code";
String redisCode = jedis.get(codeKey);
System.out.println("redisCode=" + redisCode);
if(redisCode.equals(code)){
System.out.println("success");
}else{
System.out.println("fault");
}
jedis.close();
}
public static void verifyCode(String phone){
Jedis jedis = new Jedis("Redis的IP地址", 端口号);
jedis.auth("Redis的登录密码");
String countKey = "VerifyCode" + phone + ":count";
String codeKey = "VerifyCode" + phone + ":code";
String count = jedis.get(countKey);
if(count == null){
jedis.setex(countKey, 24*60*60, "1");
} else if (Integer.parseInt(count) <= 2) {
jedis.incr(countKey);
}else if (Integer.parseInt(count) > 2){
System.out.println("今天发送次数已经超过三次");
jedis.close();
return;
}
String code1 = getCode();
jedis.setex(codeKey, 120, code1);
jedis.close();
}
public static String getCode(){
Random random = new Random();
String code = "";
for(int i = 0; i < 6; i ++){
int rand = random.nextInt(10);
code += rand;
}
return code;
}
}SpringBoot整合Jedis
1、 在pom.xml文件中引入redis相关依赖
<!-- redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- spring2.X集成redis所需common-pool2-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.6.0</version>
</dependency>2、application.properties配置redis配置
#Redis服务器地址
spring.redis.host=192.168.140.136
#Redis服务器连接端口
spring.redis.port=6379
#Redis数据库索引(默认为0)
spring.redis.database= 0
#连接超时时间(毫秒)
spring.redis.timeout=1800000
#连接池最大连接数(使用负值表示没有限制)
spring.redis.lettuce.pool.max-active=20
#最大阻塞等待时间(负数表示没限制)
spring.redis.lettuce.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.lettuce.pool.max-idle=5
#连接池中的最小空闲连接
spring.redis.lettuce.pool.min-idle=03、添加redis配置类
@EnableCaching
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
template.setConnectionFactory(factory);
//key序列化方式
template.setKeySerializer(redisSerializer);
//value序列化
template.setValueSerializer(jackson2JsonRedisSerializer);
//value hashmap序列化
template.setHashValueSerializer(jackson2JsonRedisSerializer);
return template;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}4、RedisTestController中添加测试方法
@RestController
@RequestMapping("/redisTest")
public class RedisTestController {
@Autowired
private RedisTemplate redisTemplate;
@GetMapping
public String testRedis() {
//设置值到redis
redisTemplate.opsForValue().set("name","lucy");
//从redis获取值
String name = (String)redisTemplate.opsForValue().get("name");
return name;
}
}